

AI Agent Cost Comparison 2026: The Complete Developer’s TCO Guide
Typically, a project will hit its total budget for an artificial intelligent(mh) agent or automatic intelligent agent before it puts out the first line of code when doing so is caused by three different issues layering together: the cost of the tokens used by the LLM during inference, the cost overhead associated with the model and building framework to orchestrate the engineering of the application through the building of a model; the infrastructure that consumes resources to run an AI agent and associated engineering costs, which is the total cost incurred throughout the total project.
Gartner projects the world will spend up to approximately $2.52 trillion instance toward global artificial intelligence by year 2026 (Gartner.com Global AI Industry Report). Furthermore, 59% of companies currently are budgeting for AI agent projects in the upcoming 12 months, leading to the greatest price differences between solutions for creating agents ever. For instance, using a Lang-Graph agent running in a sustainable manner on a DeepSeek V4 Flash plugin, there will be a cost for creating that agent equal to $0.002. By contrast, the same set of logic programmed to behave as part of a general-purpose auto-generating group chatting (AGG) paradigm within the new frontier model will cost at least 175 times more ($0.35 or higher) to accomplish the same task.
Consequently, the right answer to the question of how much it will cost to create an AI agent is based on a decision made by engineers rather than procured from a vendor. This guidance gives you real numbers for how much each token costs to operate (on a per-token basis and framework), each of the overheads involved with running the models used to engineer the system for creating agents, as well as what you should pay when you build-vs-buy the total build cost. Additionally, this guide will give you a set of model routing strategies that you could implement immediately.
What Is AI Agent Cost? (And Why Most Estimates Are Wrong)
When calculating the “full” cost of running an AI agent or the total expenses necessary for one Task being completed by an autonomous LLM-based system (i.e., from Initial input token to Final tool-call result), many times, Cost estimates only include “headline” token pricing. Because of this difference, teams frequently overlook their actual spending associated with running AI Agents by 2x-5x.
The true cost of operating an AI Agent consists of three separate levels:
1) LLM Inference Cost – the Per-token pricing billed by the model provider
2) Framework Orchestration Overhead – extra/buried tokens used (loop) for Planning, Coordination, and Retrying.
3) Infrastructure/Engineering Total Cost Of Ownership (TCO) – Servers, Observability tools, Security, and Engineering hours required to keep everything up in Production.
To accurately budget for an Agentic Workflow in 2026 requires understanding all three levels.
Layer 1: LLM Inference Cost What You Actually Pay Per Token
In determining the cost for any AI agent, the LLM inference cost is the fundamental metric to be analyzed. Pricing for models that are available in 2026 will have the greatest variance that has ever been seen in the AI industry; there will be low-end models offering LLM inference costs as low as $0.05 per million input tokens to high-end models with LLM inference costs as high as $5.00 per million input tokens.
Here is a list of how many models are located in each of the price point categories at the present time (June 2026) based on the per-token rates associated with each model:
Low-cost model best suited for high-volume task and for less complicated tasks:
Gemini 2.5 Flash-Lite ($0.10 per million input tokens; $0.40 per million output tokens), GPT-5 nano ($0.05 per million input tokens; $0.40 per million output tokens), DeepSeek V4 Flash ($0.14 per million input tokens; $0.28 per million output tokens) have disrupted the low-cost agent marketplace.
Medium-cost model best suited for utilizing tools and multi-step reasoning:
Claude Haiku 4.5 ($1.00 per million input tokens; $5.00 per million output tokens), GPT-5.2 ($1.75 per million input tokens; $14.00 per million output tokens), Gemini 3.1 Pro ($2.00 per million input tokens; $12.00 per million output tokens) are examples of agents that will have medium pricing.
High-cost model best suited for highly complex reasoning and synthesizing data from long-contexts:
Claude Sonnet 4.6 ($3.00 per million input tokens; $15.00 per million output tokens), Claude Opus 4.8 ($5.00 per million input tokens; $25.00 per million output tokens) are the most advanced agents available.
Why Output Tokens Hurt More Than Input Tokens
In production, output tokens are the major cost factor in agentic budgets. For example, a task generating 10,000 output tokens on Gemini 2.5 Flash-Lite costs~$0.004 and on Claude Opus 4.8 costs~$0.25: a 60x difference just based on output tokens alone. Since agents generate planning traces plus tool-call arguments and self-corrections for each loop iteration, output tokens will build up quickly.
An Interesting Fact about How Prompt Caching Can Reduce Your AI Agent Costs by Up to 70%.
Prompt caching offers the best overall leverage to reduce AI Agent API costs – especially with respect to Anthropic’s 90% discount on cached token reads. Google provides a 75% discount and OpenAI provides a 50% discount via batching for this type of use.
If an agent uses longsystem prompts, shared document contexts or retrievable results from prior requests in multiple requests, monthly inferences may be reduced by between 40% and70% without significant implementation effort.
For example, assume a customer service agent processes 10.000 requests per day, each with 1.500 input tokens and 400 output tokens, and thus processes approximately 570 million tokens per month. If the agent is using Claude Sonnet 4.6 as the underlying model, then their monthly costs would cost approximately $5,400. If they switched their underlying model to Claude Haiku 4.5, the monthly cost would then be approximately $1,800 – a $3,600 savings per month with no architectural changes made.
Pro Tip – Token Budget Management: You should always set explicit max_tokens limits on every call to an agent, and you need to enable prompt caching from the day you start using the agent. These two items alone can help you cut your monthly inference costs by over 50%, before even looking to change anything else in your architecture.
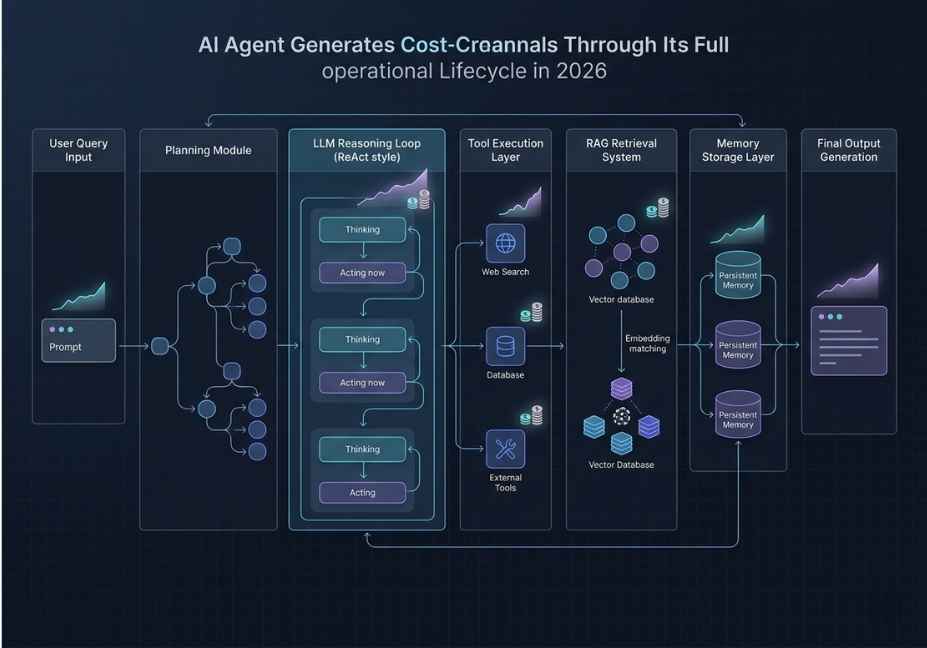
Layer 2: Framework Token Overhead The Hidden Cost Many Teams Are Missing
Selecting one of the agent frameworks isn’t just a developer-experience-related decision – it’s important to realize that each orchestration layer will consume additional tokens in addition to your raw LLM calls. In fact, there is such a great variance between the different frameworks that selecting the wrong one could result in your monthly invoice changing by up to three to five times.
Most agent loops today follow the ReAct reasoning-and-acting paradigm as detailed in a 2023 paper by Yao et al. However, there is a lot of variances between frameworks on how well they actually implement this paradigm in terms of token verbosity.
LangGraph has reduced production workloads
by employing a stateful execution model that utilizes state machines and has very low orchestration token usage, first-class persistence, and configurable checkpointing. A LangGraph agent will typically perform a standard 10-step task in only 5 to 8 LLM calls. LangGraph was the fastest and most cost-effective platform tested across 2000 benchmark runs for structured multi-step analytical tasks, making it the best starting place for any agentic production workflow where cost is important.
CrewAI has a good balance for prototyping role-based agents
Through the use of a role-based multi-agent architecture wherein each agent has a defined role, goal, and backstory. As a result of using this architecture, CrewAI typically requires moderate coordination overhead of around 6 to 10 LLM calls per 10-step task. For example, a marketing team using CrewAI deployed a five-agent content creation pipeline in two days and achieved an 89% task success rate as documented by a Deloitte case study in 2026. However, teams that transition from prototypes to production workflows often switch platforms at that point because CrewAI is more verbose than LangGraph with respect to coordination messages.
AutoGen: Powerful but Expensive at Scale
AutoGen’s GroupChat pattern accumulates the full conversation history for every agent turn. As a result, a four-agent debate running five rounds generates at least 20 LLM calls, with growing context passed into each one. Moreover, benchmarks show approximately 24% additional token overhead compared to LangGraph on equivalent tasks. Additionally, the average per-query cost on frontier models runs around $0.35. Therefore, AutoGen is expensive for high-volume, real-time use cases. However, it excels at offline, quality-sensitive workflows for instance, a software engineering team at Novo Nordisk built a ten-agent code review system that achieved 94% task completion rates in production.
Google ADK: Native Vertex AI Integration
As part of the formal announcement of the Agent Development Kit from Google, made in April 2026, they offered developers a hierarchical agent tree – a root and its children agents. In addition to that, agents built using the ADK will be able to use the ADK´s Agent-to-Agent protocol for communicating with agents built with either LangGraph or CrewAI, which is another Google’s product to provide additional custom-built agents. In typical coordination processes, most workflows will incur between six and twelve LLM calls for each one of their LLMs. Thus, when paired with Gemini Flash models, where the infrastructure cost is negligible, companies already using Google can expect very competitive pricing.
Framework Cost Comparison at a Glance
Utilizing LangChain or LangGraph agents, which will both have three (3) tools associated with each agent and include retriever augmented generation (RAG), will typically incur between $0.02 and $0.08 in API fees for each fully functioning conversation. In comparison, a similar conversation would incur between $0.20 and $0.40 when utilizing four (4) different agents in AutoGen GroupChat where all agents are doing the same logic. Thus, the choice of architectural framework, rather than the choice of logical combination model, dictates from three (3) to five (5) times the cost variance due to multi-agent use, and therefore should be assessed on a cost basis with the same level of intensity as is done for selecting a logical combination model.
Architect’s Note LangGraph vs AutoGen Cost Decision: Use LangGraph when you need production efficiency, durable state, and cost predictability. Use AutoGen when task quality matters more than per-call cost specifically for research pipelines, iterative code generation, and complex multi-agent reasoning tasks that run offline.
Layer 3: Build vs. Buy The 36-Month TCO Breakdown
When it comes to deciding if a team should create a custom agent or use a pre-packaged platform, the tangible total cost of ownership (TCO) over 36 months is where the main decision resides, and buying will typically have a lower total cost than actually creating a new agent.
What Off-the-Shelf AI Agent Platforms Cost in 2026
For example, general-purpose platforms such as Lindy, Relevance AI and n8n (which can have AI nodes) charge between $30 – $150/user/month for their users on an SMB tier. Alternatively, customer support platforms have now also moved to a more outcome-based pricing model. For example, Fin charges $0.99 for each successfully resolved conversation, but has no associated seat or platform licenses. Therefore, if you have solid resolution rates to base your costs on, you should have an easy time estimating your costs.
What Custom AI Agent Development Costs in 2026
Custom Agents – The cost of custom agents can vary greatly based on the complexity:
Generally speaking, you’ll pay between $10k – $30k to build a prototype of a custom agent, and then have monthly operating costs of about $200 – $500/month. A single-purpose Minimal Viable Product (MVP) will cost approximately $20k – $60k to build and will have monthly costs of $500 – $1500 to operate. A mid-tier enterprise-level agent (with CRM, ERP and customer support integration) would cost $60k – $150k to build and $1500 – $5000/month to operate. Finally, a full multi-agent system with the required level of security/compliance/orchestration will cost between $150k-$500k to build and will have ongoing operational costs ranging from $5k – $20k per month or higher.
The 36-Month TCO Reality
According to a real TCO analysis, operational costs are estimated to average 65%-75% of total spending over three years. Thus, operational costs generally can’t equal the initial investment for building an ML solution. When you consider all of the engineering resources (model development, MLOps infrastructure maintenance, model refreshes, security compliance, & failure mode remediation costs), the cost of DIY complex deployments would be 8-20 times more than the cost of building / deploying a pre-built solution over a period of 36 months.
The AI agent vs human agent savings story is also well documented. For instance, Telefónica was able to reduce their cost per interaction (phone call) from €3.50 to €0.35 (i.e., a 90% savings) while also increasing their call volume by 900K with voice activated automations (AI). Likewise, HelloFresh reduced their total support spend by $12M to $1.8M by switching to automating their routine inquiries (phone inquiries) using AI technology. These results did not come from teams that waited until they received an invoice for the first month of construction before estimating costs to determine if they could afford the team to construct the ML product.
By The Way…. The price of basic AI agent functionality has also declined by approximately 35% between 2023-2025, largely due to decreasing infrastructure & increased competition in the ML space. For example, basic AI agent capabilities that cost $500/month in 2022, are now available as low as $100/month.
How to Cut AI Agent Costs: The Model Routing Strategy
The lowest per-agent cost 2026 Engineering Teams do not utilize a single premium model across all their use cases. Rather, they route based upon the complexity of task — only sending those tasks that actually require frontier reasoning out to frontier models, and doing everything else in the cheapest manner possible.
These tiers are as follows…
Tier 1 Simple tasks (i.e. classifications, extractions, routing decisions & summarizations) are best served by the cheapest fast model available (e.g. Gemini 2.5 Flash-Lite at $0.10 per million input tokens or DeepSeek V4 Flash at $0.14 per million input tokens) since both provide an equivalent quality output with well-defined inputs at a small fraction of flagship costs.
Tier 2 : Medium-complexity tasks (i.e. tool usage, multi-step reasoning & code generation) are best served by best-value flagships (e.g. Claude Sonnet 4.6 at $3.00 per million input tokens). They provide an excellent balance between intent and costs. Furthermore, they support long context windows of one million tokens which eliminates long-context surcharges for the majority of RAG pipelines.
Tier 3 : Difficult tasks (i.e. compliance reviews, long-context synthesis, & challenging multi-hop reasoning chains) are well served by the use of frontier models such as Claude Opus 4.8 or GPT 5.2. Consequently, to save an additional 50% off your costs, utilize either OpenAI’s Batch API or Anthropic’s Message Batches for non-time-critical tasks.
Common Mistakes That Inflate AI Agent Costs (And How to Fix Them)
Mistake 1: Not Capping Reasoning Tokens
Because reasoning algorithms bill for every hidden thinking token at the full output rate (e.g., calling a single GPT-5.2 Pro can use 50,000 output tokens before returning an answer to an entire paragraph), ensure you always set very tight max_tokens limits for non-reasoning tasks and reserve extended reasoning for those examples that truly require it.
Mistake 2: Skipping Prompt Caching
When your agent uses a long system prompt or retrieves a shared document across multiple requests, and you do not cache, then you are paying full price for tokens you already processed. In addition, every major vendor is capable of providing caching support. Since the implementation of caching usually requires only a minor configuration change rather than a comprehensive re-architecting, there are really no good reasons you should not implement it.
Mistake 3: Using AutoGen for High-Volume Real-Time Tasks
While AutoGen is great for developing quality-conscious offline research and code review solutions, AutoGen is a poor solution for customer support or real-time tool-using agents because the cost-per-call is significantly higher than LangGraph or a small custom ReAct loop will deliver at 3 to 5 times lower cost per call using the same work.
Mistake 4: Ignoring the Long-Context Surcharge
Pricing models tend to increase based on context thresholds that have been defined for each model. An example would include Gemini 3.1 Pro where input rates will be doubled after 200,000 tokens are used. In addition, if you are utilizing a RAG pipeline that pulls many large documents into the agent’s context window, model-specific pricing curves need to be included as part of your cost model rather than only including the base per-million token rate.
Mistake 5: Building When You Should Be Buying
If you are planning to implement an AI agent for a specific use case such as customer support, IT Helpdesk, or lead qualification, then you should consider using a pre-built platform which will often times be lower in TCO (Total Cost of Ownership) over 36 months than an equivalent custom-built solution. Build custom only if your workflow is so unique that an off-the-shelf solution would not be able to meet your needs.
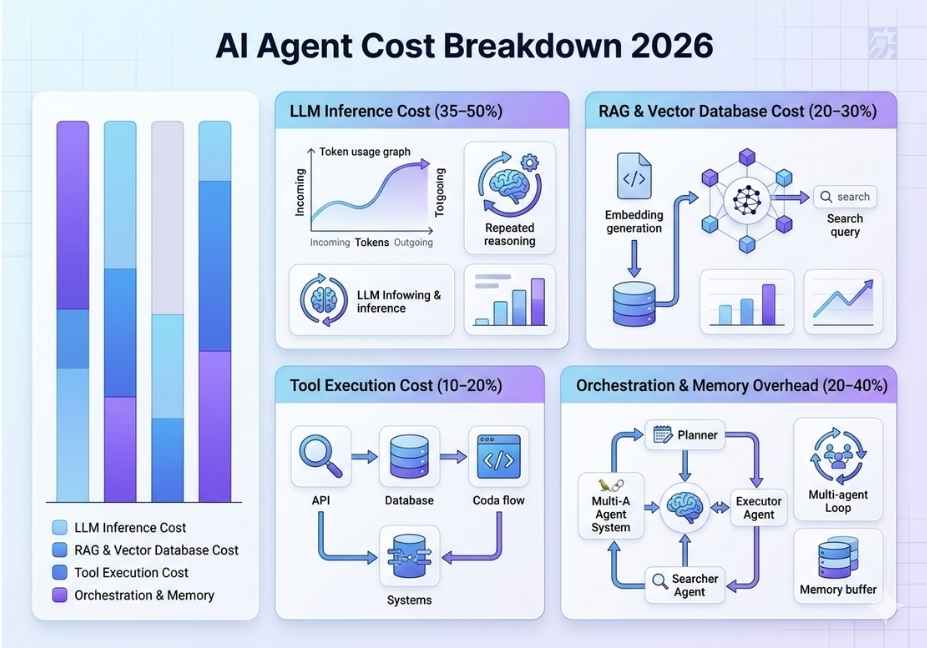
FAQ People Also Ask
How much does it cost to run an AI agent in 2026?
Using an AI Agent in 2026 will cost you between $0.002 to $0.50 per task depending on what model, framework and how complex your workflow is going to be. For example, a simple LangGraph Agent running on Gemini 2.5 Flash-Lite would only cost $0.002 to $0.02 per run compared to a frontier model AutoGen multi-agent workflow would cost $0.20 to $0.50 per execution. The estimated monthly production costs will vary; however you could expect to spend approximately $200 per month for small automations or $20,000+ per month for enterprise multi-agent deployments.
What is the cheapest LLM for AI agents in 2026?
For 2026, the LLM models available at the lowest prices for AI agents will be the GPT-5 nano at $0.05 per million input tokens, the Gemini 2.5 Flash-Lite at $0.10, and the DeepSeek V4 Flash at $0.14 per million input tokens. These types of LLMs do a similar job in performing well-defined tasks (like classification and extraction) as do mid-level LLMs, but at a fraction of the price. However, they are not suitable for tasks involving complex reasoning, long context synthesis, or the agentic variety of tool-use chains which require deeper levels of planning.
Is it cheaper to build or buy an AI agent in 2026?
Purchasing an off-the-shelf (OTS) AI agent platform is more cost-effective than building a custom solution for 36 months for OTS use cases. The fully-loaded costs of building a custom solutions increase 8-20x compared to using an OTS solution once you factor in engineering time, MLOps infrastructure, security, and ongoing maintenance. Therefore, build a custom solution only when you have a workflow that is truly too unique for any off-the-shelf solution to accommodate.
How does prompt caching reduce AI agent costs?
Prompt caching enables the reuse of previously processed tokens (e.g. system prompts, shared documents and retrieved results) by model suppliers at significant savings on subsequent calls. Caching saves up to 90% for cached token reads provided by Anthropic, 75% for Google and 50% for OpenAI through its Batch API. Because agents utilize consistent system prompts or repeat retrieval of documents, the average monthly inference bill for cached tokens can be reduced by 40 to 70%.
Which AI agent framework has the lowest token overhead?
As per a report on 2026 development tools, LangGraph has provided the least amount of token overhead across all of the major frameworks with the implementation of 5-8 LLM calls plus some coordinative tokens when processing a standardized 10-step pipeline. In contrast, CrewAI falls toward the middle with an estimated 6-10 total calls per workflow. AutoGen’s design relies heavily on accumulated conversation history requiring 8-15 separate calls to execute the same type of project. Using LangGraph will therefore provide the most cost effective solution for implementing large volume production workloads.
What is the true total cost of a multi-agent system?
When evaluating the total costs involved in creating a robust multi-agent system including LLM inference charges and framework coordination tokens, you must also take into account the costs associated with message overhead per agent, memory retrieval fees, observability tooling, and retry costs associated with your failure modes. In many cases coordination overhead is the largest contributor (30%-50%) of total costs for LLM-based systems and therefore determining the type of framework based on context management should not only be considered from an architectural perspective but also as part of evaluating the overall cost associated with the multi-agent system.
Conclusion
To achieve AI Agent Costs Below Threshold In 2026, There Are Three Sequential Decisions.
1) Choose LLM (Language Model) Based On Task Complexity, NOT Brand. $0.05 to $5.00/1 Million Tokens is a Massive Distribution That Captures Speed Well At Production Levels.
2) Choose Framework Based On Throughput (Production Speed). LangGraph Has Much Less Coordination Overhead Than AutoGen, and Represents A Real Cost Advantage In Production Workloads. AutoGen is Better Suited for Offline Quality Sensitive Workflows Than LangGraph.
3) Model Your Total Cost of Ownership (TCO – Over 36 Mos.) Before Committing To Custom Builds. The Operational Costs Will Always Be Several Times Greater Than The Initial Development Investment, and Build vs. Buy Cost Comparisons Will Show That There Are More Favourable Options In Pre-Built Platforms Than Any Engineering Team Anticipates.
Developers Running The Most Cost-Efficient Production Agents Today Are Not Optimising
A Single Variable; They Are Directing By Task Complexity, Caching As Much As Possible (Before Day 1) And Auditing Cost By Framework & Model (Before Scaling – Not After Being Surprised By An Invoice).
Bookmark This Guide And Check Out Additional Hands-On Tutorials For Building AI Agents At Http://www.agentiveaiagents.Com Anyone Can Build A High Cost/Efficiency Agent Using These Steps.






One Comment