

Market Research Strategy Template: The Complete Agentic AI Guide (2026)
The majority of market research projects do not deliver results successfully after the gross expenditures that go into them being reflected in their overall costs for the time period when completed. As opposed to being attributed to poor data sources for failure, the reasons for project failures are due to the manual, siloed, and non-scalable form of workflow that exists in the majority of market research operations today. Qualtrics’ 2026 study found that 89% of the respondents reported using AI tools on a consistent basis. However, over the half still utilize segregated pipelines that exist with one analyst pulling together report data, other analysts pulling data from surveys, and another compiling all of the findings together three weeks after the submission of an analysis; i.e., A/B testing.
The major impediment to success in the majority of these projects stems from the architecture and not the intelligence.
By leveraging an agentic architectural approach to market research strategy templates, the workflow transfers from a static checklist to a dynamic pipeline. A system of agents is established to decompose the research brief for its deliverables; agents retrieve real-time market signals through the use of retrieval problem-solution methods; run competitive profiles for each of the total solutions being identified via the use of tools; and produce decision-ready reports for the end users automatically.
The objective of this article is to provide the reader with an overall template of the agentic system and its agentic architectural breakdown; tools for execution within the framework of the agentic system; scaffolding for execution via Python; and failure modes to which teams succumb prior to the release of their first report.
Short Answer: A market research strategy template is an organized, phase-by-phase plan that communicates the objectives of the research, as well as data collection and analysis processes and outputs.
What Is a Market Research Strategy Template?
A market research strategy template is a structured framework that defines the sequence, methods, and outputs for gathering and synthesizing market intelligence. Traditionally, these templates live in spreadsheets or Notion pages static checklists covering objectives, target audience, research methods, and deliverables.
In agentic AI systems, however, the same template becomes an orchestrated pipeline. Each phase maps to a tool-use step: web search agents handle data collection, embedding models index retrieved content into a vector store, and an LLM synthesis agent produces the final report. As a result, the template isn’t just documentation it’s the system prompt that governs autonomous LLM agents for market research tasks.
Furthermore, a well-structured template solves the three most common research failures:
- Scope creep : agents without a defined brief hallucinate irrelevant subtopics
- Data staleness : static reports miss real-time market signals
- Synthesis gaps : disconnected tools produce outputs nobody can act on
Technical Note: In LangChain terminology, a market research strategy template maps directly to an agent executor plan a sequence of tools, memory retrievals, and synthesis steps chained through a ReAct-style loop.
How to Build a Market Research Strategy Template Step by Step
Building an effective market research strategy template requires five clearly defined phases. Each phase maps to a specific agent action in an agentic workflow. Consequently, the better you define each phase upfront, the more reliably your agents execute downstream.
Phase 1 : Brief Definition (Inputs)
- Research question (specific and time-scoped)
- Target market and customer segment
- Geographic and temporal scope
- Deliverable format: report, dashboard, or JSON
- Deadline and urgency tier
Phase 2 : Data Collection Plan
- Secondary sources: industry reports, public filings, competitor websites, academic papers
- Primary sources: surveys, interviews, social listening (Reddit, LinkedIn)
- Agent tools to use: SerpAPI, Jina AI, arXiv API, Crunchbase API
Phase 3 : Analysis Framework
- Competitive landscape using Porter’s Five Forces and SWOT
- Market sizing through TAM/SAM/SOM with Python-backed calculations
- Customer persona development and validation
- Trend extraction plus signal clustering
Phase 4 : Synthesis and QA
- Completeness check against the original brief
- Hallucination audit: cross-reference agent claims against raw sources
- Confidence scoring per individual claim
Phase 5 : Output Delivery
- Executive summary of 500 words or fewer
- Full structured report with inline citations
- Action items and strategic recommendations
Pro Tip: Version-control your template alongside your agent system prompts. When you update Phase 3’s analysis framework, update the orchestrator’s corresponding system prompt at the same time they must stay in sync or your agents will drift off-brief.
The Six Core Components of an Agentic Market Research Framework
Every solid market research strategy template whether manual or agent-driven contains six structural components. Here is how each one maps to an agentic implementation:
1. Research Objective Definition This translates directly to the initial system prompt given to the orchestrator agent. Specificity matters enormously. For example, “Analyze EV battery market in Germany 2023–2026” outperforms “tell me about EVs” by several orders of magnitude in output quality.
2. Target Audience and Persona Layer In agentic systems, this component feeds the retrieval filter the agent only ingests sources relevant to the defined customer segment. LlamaIndex’s metadata filtering handles this cleanly at the vector store level.
3. Primary Research Module AI interview agents from platforms like Outset or Conveo can now run full interview loops: recruitment, scheduling, and open-ended questioning. Additionally, the output feeds directly into the synthesis layer without manual transcription.
4. Secondary Research Module This is where RAG genuinely shines. Agents query SerpAPI, arXiv, public filings, and industry databases, then chunk and embed retrieved content into a vector store Pinecone, Chroma, or Weaviate for semantic retrieval.
5. Competitive Intelligence Layer A dedicated sub-agent performs TAM/SAM/SOM analysis, SWOT extraction, and pricing benchmarks. Moreover, tool-use loops run Python calculations against retrieved data rather than relying purely on text generation.
6. Synthesis and Output Execution Finally, the synthesis agent assembles section drafts, generates an executive summary, and formats the report in Markdown or a structured JSON schema for downstream consumption.
[Insert diagram: Six-component agentic market research framework showing objective → persona → primary research → secondary RAG → competitive intelligence → synthesis output]

How AI Agents Automate Each Phase of Your Research Workflow
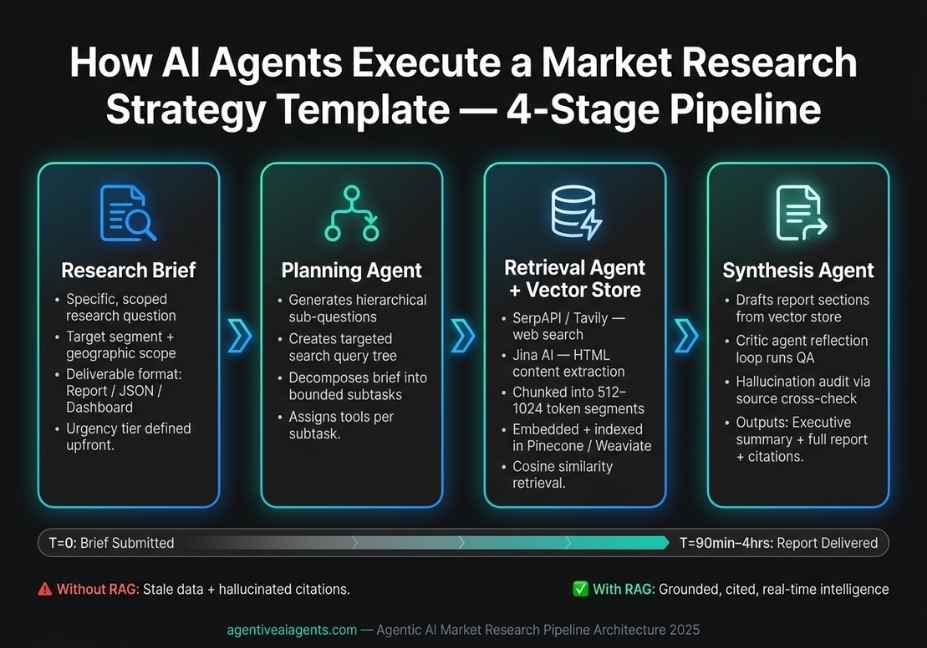
The key architectural insight behind building a multi-stage market research AI agent is task decomposition: breaking the research brief into discrete, bounded subtasks that individual agents or tools can execute reliably.
Here is a concrete four-stage agentic pipeline:
Research Brief
↓
[Planning Agent] → generates sub-questions + search queries
↓
[Retrieval Agent] → SerpAPI + web scraping + PDF extraction
↓
[Embedding + Vector Store] → Pinecone / Chroma (semantic chunking)
↓
[Synthesis Agent] → structured report (Markdown/JSON)In practice, the planning agent generates a tree of sub-questions before any retrieval begins. This hierarchical query decomposition approach is one of the single highest-leverage architectural improvements you can make. Furthermore, it prevents the retrieval agent from running broad, low-signal searches that pollute the vector store with irrelevant content.
Minimal Python scaffold using LangChain:
python
from langchain.agents import initialize_agent, AgentType
from langchain.tools import Tool
from langchain_community.tools import SerpAPIWrapper
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI(model="gpt-4o", temperature=0)
search = SerpAPIWrapper()
(tools = Tool)
name="Search",
func=search.run,
[description="Search for market data, competitor info, and industry reports."]
(memory = ConversationBufferMemory
memory_key="chat_history",
return_messages=True)
(agent = initialize_agent
tools=tools,
llm=llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True)
# Example: scoped, specific research brief
agent.run
("Analyze the EV charging infrastructure market in Germany. "
"Cover market size, top 5 competitors, pricing benchmarks, "
"and 2026 growth projections. Cite sources.')Pro Tip: Add a reflection pattern between the retrieval and synthesis stages. Specifically, have a critic agent score each retrieved source for relevance before it enters the vector store. This one change dramatically reduces hallucination risk in the final report.
Best Tools and Frameworks for AI-Powered Market Research
Choosing the right tools determines whether your agentic market research pipeline ships in a week or stalls indefinitely. Therefore, here is a framework-level comparison across the most commonly used options:
| Tool | Category | Best For | Key Limitation |
|---|---|---|---|
| LangChain | Orchestration | Multi-tool agent pipelines, memory management | Rapid API changes always check current docs |
| LlamaIndex | RAG / Indexing | Document ingestion, vector store integration | Less flexible for real-time web data |
| AutoGen | Multi-agent | Parallel agent collaboration, critic patterns | Higher latency in multi-turn workflows |
| SerpAPI | Web Retrieval | Real-time search result extraction | Rate limits and cost at scale |
| Tavily | Web Retrieval | AI-optimized search with structured output | Newer; smaller ecosystem than SerpAPI |
| Pinecone | Vector Store | Production-grade semantic retrieval | Hosted only; pricing tier required |
| Chroma | Vector Store | Local dev and open-source workflows | Not production-ready out of the box |
| Weaviate | Vector Store | Hybrid search (vector + keyword combined) | More complex setup than Chroma |
| n8n | Workflow Automation | No-code agent orchestration | Limited custom Python logic |
| Relevance AI | End-to-end | Pre-built market research agent templates | Less granular control over pipeline steps |
Architect’s Note: For teams starting out, LangChain + Chroma + SerpAPI is the fastest path to a working local pipeline. For production deployments, swap Chroma for Pinecone and add LangSmith for observability. Additionally, Arize works well for monitoring LLM output quality in real-time research pipelines.
According to Foundation Capital’s analysis, AI agents will redefine the market research stack across three distinct layers data collection, workflow automation, and output execution with the biggest disruption already happening at the primary research layer.
How to Use RAG in a Competitive Intelligence Workflow
Retrieval-Augmented Generation is the backbone of any reliable agentic market research pipeline. Without RAG, your LLM synthesizes from parametric memory alone which means stale data, fabricated citations, and low confidence scores.
Here is how RAG integrates into the competitive intelligence layer specifically:
Step 1 : Document Ingestion The retrieval agent fetches competitor websites, earnings filings, analyst reports, and academic papers. Jina AI handles content extraction from complex HTML pages, while arXiv and Crunchbase APIs handle structured data sources.
Step 2 : Chunking and Embedding Retrieved documents are chunked into 512–1024 token segments and embedded using a model like text-embedding-3-large. The embedding model converts text into high-dimensional vectors that capture semantic meaning.
Step 3 : Vector Store Indexing Embedded chunks are indexed into Pinecone or Weaviate. Weaviate is particularly valuable here because it supports hybrid search combining vector similarity with keyword matching for higher-precision competitive intelligence retrieval.
Step 4 : Semantic Retrieval at Synthesis Time When the synthesis agent drafts the competitive analysis section, it queries the vector store using cosine similarity retrieving the most semantically relevant chunks rather than relying on exact keyword matches. This is why RAG dramatically outperforms a basic web search-and-summarize approach.
Step 5 : Grounded Output with Citations The synthesis agent generates claims anchored to specific retrieved source chunks. Each claim includes a confidence score and a direct reference to the originating document segment.
Did You Know? A 2026 Qualtrics Market Research Trends Report found that 83% of research organizations plan to increase AI investment, yet fewer than 20% have implemented a structured RAG pipeline for competitive intelligence. That gap is your competitive advantage.
AI-Powered Market Research Template: Real-World Use Cases
Understanding how teams apply this template in practice helps clarify which components matter most for different contexts. Here are three concrete examples:
Use Case 1 : Startup Product-Market Fit Research A B2B SaaS startup uses the template to run a two-agent pipeline: a retrieval agent scans Product Hunt launches, G2 reviews, and Reddit discussions in r/entrepreneur, while the synthesis agent identifies unmet pain points in the target segment. The entire research cycle runs in under 90 minutes, compared to two weeks manually.
Use Case 2 : Enterprise Competitive Intelligence An enterprise strategy team deploys a multi-agent system using AutoGen. One agent monitors competitor earnings filings weekly. A second agent tracks pricing page changes via web scraping. A third agent synthesizes both feeds into a weekly competitive briefing delivered as a structured JSON report to their BI dashboard.
Use Case 3 : Market Sizing for Investor Due Diligence A VC analyst uses LlamaIndex with Crunchbase and arXiv APIs to automate TAM/SAM/SOM calculations for portfolio company assessments. The agent retrieves industry sizing reports, extracts numerical data using a Python tool-use loop, and populates a pre-defined financial model template reducing due diligence research from 3 days to 4 hours.
Common Mistakes That Break Agentic Market Research Pipelines
Even well-designed market research strategy templates fail in production when developers skip these critical safeguards. Here are the five most damaging mistakes and how to fix each one:
Mistake 1: Skipping Source Validation Agents hallucinate citations with confidence. Therefore, always implement a completeness evaluator that cross-references agent claims against the raw retrieved documents. A cosine similarity check between the cited source chunk and the final claim in the report catches most fabrications before they reach the reader.
Mistake 2: Treating the Template as a Static Document Your market research strategy template should version-control alongside your agent prompts. When you update the research brief structure, update the orchestrator’s system prompt simultaneously they need to stay perfectly in sync.
Mistake 3: Over-Relying on Secondary Data Only LLMs are excellent at synthesizing public information. Nevertheless, 89% of researchers using AI tools still report that primary research interviews and surveys produces higher-confidence strategic insights. Build both layers into your pipeline from the start.
Mistake 4: No Memory Across Research Sessions If your agent doesn’t persist findings across runs, you’ll re-retrieve the same data repeatedly. As a result, costs escalate and synthesis quality degrades. Use a persistent vector store or a structured JSON state file that accumulates research context across sessions.
Mistake 5: Vague Research Objectives The quality of your agentic research output is directly bounded by the specificity of the initial brief. For example, “Competitive analysis of fintech” returns noise. In contrast, “Competitive analysis of embedded lending products for SMBs in Southeast Asia, Q1–Q3 2026” returns actionable signal.
What Developers Are Saying About Agentic Market Research
On Reddit’s r/LocalLLaMA and r/MachineLearning, the consistent debate centers on depth versus breadth in agentic research pipelines. Specifically, agents that run 40 narrow targeted searches consistently produce higher-quality reports than those running 5 broad ones. Several practitioners advocate for hierarchical query decomposition where the planning agent generates a tree of sub-questions before any retrieval begins as the single highest-leverage architectural improvement.
Furthermore, GitHub discussions on the LangChain and LlamaIndex repos show active experimentation with reflection loops: having a critic agent score report sections against the original brief before the final synthesis pass. Teams that implement this pattern report significantly fewer hallucinated citations and better coverage of the stated research objectives.
One recurring thread on r/MachineLearning highlights a key insight worth noting: the best agentic research pipelines treat the market research strategy template itself as a living artifact not a fixed input, but something the planning agent can iteratively refine based on what early retrieval passes reveal.
FAQ People Also Ask
What is a market research strategy template?
A market research strategy template is a structured framework that defines research objectives, data collection methods, analysis approach, and deliverable format for a market intelligence project. In agentic AI systems, it also functions as the orchestration blueprint governing which tools, retrieval steps, and synthesis agents execute at each phase of the pipeline.
How do AI agents automate market research?
AI agents decompose the research brief into subtasks, execute web searches and document retrieval via tool-use loops, embed retrieved content into a vector store for semantic search, and synthesize findings through an LLM. Multi-agent architectures additionally add a critic layer that validates claims before the final report is assembled reducing hallucination risk in competitive intelligence outputs.
What are the key components of a market research framework?
The six core components are: (1) research objective definition, (2) target audience and persona specification, (3) primary research module including interviews and surveys, (4) secondary research module covering web, reports, and filings, (5) competitive intelligence layer for SWOT and TAM/SAM/SOM analysis, and (6) synthesis and output execution. In agentic workflows, each component maps to a specific tool or sub-agent.
How is RAG used in competitive intelligence?
Retrieval-Augmented Generation allows agents to retrieve real-time documents competitor websites, earnings filings, industry reports chunk them into a vector store, and retrieve semantically relevant passages during synthesis. This grounds LLM outputs in actual source material rather than parametric memory, significantly improving citation accuracy and factual grounding compared to standard summarization approaches.
What tools do AI agents use to gather market data?
The most common tool stack includes SerpAPI or Tavily for web search, Jina AI for content extraction, Pinecone or Weaviate for vector storage, and arXiv plus Crunchbase APIs for specialized data. LangChain or LlamaIndex typically serves as the orchestration layer. Production pipelines also add LangSmith or Arize for observability and output quality monitoring.
What is the difference between primary and secondary research in agentic workflows?
Secondary research is automated through web retrieval and RAG agents execute this at scale with minimal human input. Primary research such as interviews and surveys is increasingly agent-assisted, but still benefits from human oversight on question design and insight interpretation. The highest-quality research pipelines combine both layers, with secondary research informing the primary research instrument design before any interviews begin.
How long does it take to build a market research strategy using AI agents?
A well-configured agentic research pipeline can complete a structured competitive intelligence report in 90 minutes to 4 hours, depending on scope. In contrast, the same research done manually typically takes 2 to 3 weeks. However, initial pipeline setup, prompt engineering, and QA calibration add 1 to 2 days of upfront investment before the first automated run.
Can I use a free market research strategy template for AI agent workflows?
Yes. The five-phase template structure outlined in this guide is fully usable without paid tools. Specifically, you can build a functional pipeline using LangChain (open-source), Chroma (open-source), and SerpAPI’s free tier for low-volume research. For higher-volume production use cases, however, Pinecone and a paid SerpAPI plan become necessary investments.
Conclusion
A market research strategy template is no longer just a planning document. In 2026, it is an executable pipeline specification. Furthermore, the teams consistently winning on market intelligence have mapped each template phase to a specific agent tool retrieval, vector indexing, competitive analysis, and synthesis all running autonomously, with human review at the output layer rather than the input layer.
Three takeaways to act on immediately: First, build your template in two synchronized layers the human planning brief and the corresponding agent system prompt. Second, add a reflection and critic pass between retrieval and synthesis to eliminate hallucinated citations before they reach stakeholders. Third, never skip primary research. The highest-confidence insights still come from direct customer data, even when the agent conducts the interviews.
Bookmark this guide and explore more hands-on AI agent tutorials at agentiveaiagents.com.






6 Comments