

Agentive AI vs Agentic AI: The Architectural Difference That Matters in 2026
Most AI systems fail in production because the architecture was chosen for the wrong reasons not because the model was bad.
The debate between agentive AI and agentic AI is one of those foundational decisions that shapes every downstream engineering choice: how much autonomy you grant the LLM, whether human-in-the-loop checkpoints exist, and whether your system uses a simple tool-use loop or a full planning module with multi-step task decomposition.
These two terms are routinely used interchangeably. That conflation is dangerous. Agentive AI augments humans. Agentic AI replaces human decision steps entirely. They operate on different trust models, different failure modes, and different orchestration patterns and choosing the wrong one has real costs.
This piece breaks down both architectures precisely, compares them across the dimensions that matter to practitioners, and gives you a decision framework for choosing the right pattern for your production system.
What Is Agentive AI?
Agentive AI refers to AI systems designed to assist and augment human decision-making not replace it. The system acts on behalf of a human, but the human retains final authority at each critical step.
Think of GitHub Copilot suggesting a function completion, or a writing assistant proposing a revised paragraph. The LLM generates; the human approves. This is the core loop.
Agentive systems typically implement a lightweight feedback loop: the model proposes, the user confirms or redirects, and the system updates. There is no autonomous execution across multi-step workflows without explicit human instruction at each junction.
The defining characteristic is human-in-the-loop (HITL) by design not as a safety bolt-on, but as the fundamental interaction model.
Technical Note: In classical AI terminology, “agentive” derives from “agency” but in the modern LLM context it specifically refers to systems where the LLM functions as an augmentation layer, not an autonomous executor.

What Is Agentic AI?
Agentic AI describes systems where the LLM operates with genuine autonomy across multi-step tasks perceiving context, planning a sequence of actions, calling tools, evaluating outputs, and adapting its approach without human intervention at each step.
The architecture is fundamentally different. Where agentive AI has a human closing every loop, agentic AI implements a planning module that reasons across time, a tool-use loop that executes actions against real systems, and a memory retrieval layer that maintains context across turns.
The foundational framework underlying most agentic systems today is the ReAct pattern introduced in ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2023) which interleaves chain-of-thought reasoning with concrete tool calls in a Thought → Action → Observation loop.
Agentic AI is not simply “more automated” agentive AI. It represents a qualitatively different approach to LLM deployment: one where the model is the decision-maker, not just the suggestion engine.
Did You Know? According to the 2025 AI Agent Index, the majority of enterprise-deployed agentic systems in 2026 use LLM-based workflow builders with agentic action nodes not pure end-to-end autonomy. Full autonomy remains the edge case, not the norm.
Agentive AI vs. Agentic AI: Side-by-Side Comparison
The table below captures the architectural and operational differences across the dimensions that matter most in production.
| Dimension | Agentive AI | Agentic AI |
|---|---|---|
| Human oversight | Required at each critical step | Minimal or conditional (HITL gates) |
| Task scope | Single-step or short workflows | Multi-step, cross-system workflows |
| Planning module | None or shallow | Full task decomposition |
| Tool-use loop | Optional / limited | Core architectural component |
| Memory | Session-scoped or none | Persistent memory retrieval |
| LLM role | Suggestion engine | Autonomous decision-maker |
| Failure mode | User catches errors in real time | Silent failures across multi-step chains |
| Risk profile | Low operational risk | High autonomous actions on live systems |
| Example systems | GitHub Copilot, Claude drafts | AutoGPT, LangChain agents, AutoGen |
Key insight: The table above also maps to your governance requirements. Agentive AI poses primarily informational risk (a bad suggestion the user accepts). Agentic AI poses operational risk it takes actions on live APIs, databases, and systems without a human reviewing each step.
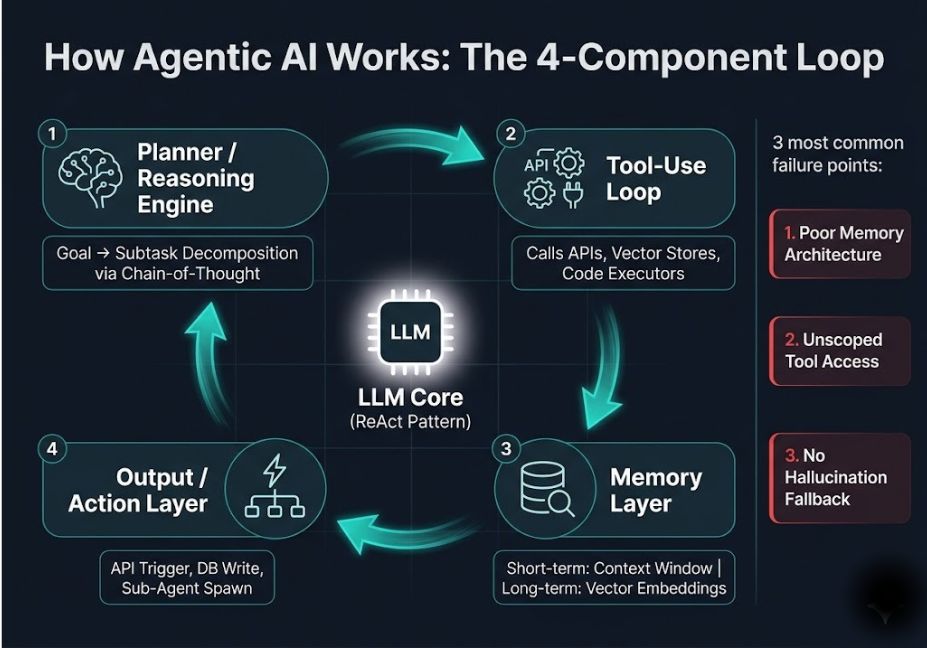
How Agentic AI Actually Works: The Architecture
For developers building on LangChain, AutoGen, or LlamaIndex, the architecture of agentic AI resolves into four components that interact in a continuous loop.
1. Planner / Reasoning Engine The LLM receives a high-level goal and decomposes it into subtasks using chain-of-thought prompting. This is where task decomposition happens the system figures out what it needs to do and in what order before acting.
2. Tool-Use Loop The agent calls external tools APIs, vector stores, code executors, search engines, databases to gather information or take action. LangChain’s agent execution loop implements this as a cycle of tool invocation, result parsing, and updated reasoning.
3. Memory Layer The agent maintains state across steps. Short-term memory holds the current context window. Long-term memory uses vector embeddings stored in a vector database (Pinecone, Chroma, Weaviate) and retrieved via semantic similarity search. This is the layer most developers underinvest in and the one most responsible for production failures.
4. Output / Action Layer The agent produces a final output, triggers an API call, writes to a database, or spawns a sub-agent. In multi-agent systems as in AutoGen’s multi-agent conversation framework (Wu et al., 2023) multiple specialized agents hand off tasks between each other, coordinated by an orchestration layer.
Pro Tip: Before deploying any agentic system in production, map your tool-use loop explicitly. Every tool the agent can call is a potential blast radius if reasoning goes wrong. Scope tool access to the minimum required for the task.
Agentive AI Use Cases: When Augmentation Is the Right Choice
Agentive AI is not the lesser architecture it is often the correct one. Use it when:
- Human judgment is irreplaceable. Legal review, medical triage, financial advisory domains where the cost of an autonomous error is catastrophic.
- The workflow has low repeatability. If tasks are highly contextual and vary significantly per instance, human-in-the-loop checkpoints preserve quality.
- You need explainability. Regulated industries (finance, healthcare, insurance) frequently require that a human approved each decision. Agentive AI makes that audit trail clean.
- You are in early deployment. Starting agentive gives you time to observe LLM behavior before removing oversight. Lilian Weng’s canonical breakdown of LLM agent architecture is a useful reference for understanding where autonomous failure points typically emerge before you consider removing HITL.
Real-world examples:
- AI code review tools that surface issues for engineer approval
- LLM-assisted email drafting (the user sends; the model writes)
- Medical documentation assistants that flag items for clinician sign-off
- Legal contract summarization with attorney review gates
Agentic AI Use Cases: When Full Autonomy Unlocks Real Scale
Agentic AI earns its complexity premium in workflows where:
- Volume makes human-in-the-loop impractical. Processing thousands of support tickets, monitoring infrastructure, or running competitive research pipelines at scale.
- Tasks are well-structured and outcomes are verifiable. Code generation and execution in sandboxed environments, data pipeline maintenance, or automated regression testing.
- Speed is a hard constraint. Cybersecurity response, real-time bidding optimization, or logistics rerouting where human review latency is unacceptable.
Real-world examples:
- Autonomous research agents scraping, summarizing, and synthesizing market data
- Multi-agent customer support systems that resolve Tier-1 tickets end-to-end
- Agentic coding assistants (Claude Code, Devin) that write, test, and iterate without developer input per step
- LangGraph-based workflow automation that coordinates across CRM, calendar, and communication APIs
Architect’s Note: Agentic AI delivers outsized value when the task has a clear success criterion you can evaluate programmatically. Without a reliable evaluation function, the agent has no signal for self-correction and failures compound silently.
Common Mistakes When Building Both Systems
Mistake 1: Choosing agentic because it sounds more advanced. Autonomy introduces operational risk. If your use case requires human judgment at any critical decision point, adding autonomy does not improve outcomes it hides errors. Match the architecture to the risk model, not the marketing.
Mistake 2: Ignoring memory design in agentic systems. Most agentic failures in production trace back to poor memory architecture either context windows overflow with irrelevant history, or the retrieval layer surfaces stale embeddings. The memory layer is not a detail; it is load-bearing.
Mistake 3: Treating HITL as optional in agentive systems. Agentive AI’s value proposition is the human closing the loop. Systems that bill themselves as agentive but rarely surface decisions to humans for review have quietly drifted into agentic territory without the architectural safeguards agentic systems require.
Mistake 4: Skipping tool access scoping. In agentic systems, every tool in the tool-use loop is a live system the LLM can affect. Without explicit scoping what the agent can read, what it can write, what it can trigger a hallucination or reasoning error can have real-world consequences across downstream systems.
Mistake 5: No fallback for LLM hallucination. Neither architecture is immune. In agentive systems, humans catch hallucinations before they act. In agentic systems, hallucinations propagate through the tool-use loop. Build verification steps output validators, assertion checks, or human-gated checkpoints at high-risk action nodes.
Framework Comparison: What to Build With
| Framework | Best For | Agentive or Agentic | Key Feature |
|---|---|---|---|
| LangChain | General-purpose agents | Both | ReAct agents, tool integrations |
| LangGraph | Stateful, cyclical workflows | Agentic | Graph-based flow control |
| AutoGen | Multi-agent collaboration | Agentic | Conversable agent architecture |
| LlamaIndex | RAG-heavy agentic pipelines | Agentic | Deep vector store integration |
| Semantic Kernel | Enterprise .NET/Python systems | Both | Planner + plugin architecture |
| CrewAI | Role-based multi-agent teams | Agentic | Agent role definition, task routing |
Technical Disclaimer: Framework versions evolve rapidly. Code examples in this article reference LangChain v0.3+ and LlamaIndex v0.10+ as of Q2 2026. Always check the official documentation for the latest API changes before deploying.
FAQ People Also Ask
What is the difference between agentive AI and agentic AI?
Agentive AI augments human decision-making the model suggests, the human approves. Agentic AI replaces human steps with autonomous planning and execution across multi-step workflows. The core difference is whether a human closes each decision loop (agentive) or the LLM does (agentic). Both use large language models; they differ in trust model and operational architecture.
Is agentive AI the same as a copilot?
Largely yes. Copilot-style tools GitHub Copilot, Microsoft Copilot, Claude in document editors are canonical examples of agentive AI. The LLM generates output that a human reviews and acts on. The human retains agency; the model provides leverage. Some enterprise copilots blur this line by automating follow-through actions, which edges them toward agentic territory.
When should you use agentic AI instead of agentive AI?
Use agentic AI when task volume makes human-in-the-loop review impractical, when tasks are well-structured with verifiable success criteria, and when speed constraints rule out human review latency. Prefer agentive AI in high-stakes domains requiring audit trails, in early deployment stages, or any time the cost of an autonomous error outweighs the efficiency gain.
What frameworks support agentic AI workflows?
LangChain, LangGraph, AutoGen, LlamaIndex, CrewAI, and Semantic Kernel all support agentic workflow patterns. LangGraph is particularly well-suited for stateful, cyclical agentic flows. AutoGen excels at multi-agent systems. LlamaIndex is the strongest choice when agentic behavior is tightly coupled with RAG pipelines and vector retrieval.
Can agentive and agentic AI work together in the same system?
Yes and this is increasingly common in production. A practical pattern: an agentive layer handles user-facing interaction and high-stakes decisions (with HITL checkpoints), while agentic sub-agents execute well-scoped backend tasks autonomously. The orchestration layer routes between them based on risk level and task structure. This hybrid architecture gives you the safety of agentive design with the scale of agentic execution.
Conclusion
The agentive vs. agentic distinction is not semantic it is architectural, operational, and consequential.
Three takeaways for practitioners:
- Match architecture to risk model first. Autonomous execution is only appropriate when failure modes are recoverable, success criteria are verifiable, and tool access is scoped. Otherwise, agentive AI with human-in-the-loop checkpoints is the safer and often better-performing design.
- Memory and tool scoping are the two highest-leverage components in agentic systems. Most production failures trace to one of these not to the LLM itself.
- The ReAct pattern is the foundation. Whether you build on LangChain, AutoGen, or LlamaIndex, you are working with a variant of the Thought → Action → Observation loop. Understanding that loop is the prerequisite to debugging it.
Agentive AI vs. agentic AI is a decision you make with every LLM system you ship. Make it deliberately.
Bookmark this guide and explore more hands-on AI agent architecture breakdowns at agentiveaiagents.com.


9 Comments