

Conversational AI Assistant: The Complete Agentic Architecture Guide (2026)
Most conversational AI assistants fail in production not because the underlying language model is weak, but because the memory architecture, retrieval grounding, and tool-use loop are poorly designed. A developer can bolt a chat interface onto GPT-4 in an afternoon. Building a system that actually remembers users, retrieves accurate context, and recovers gracefully from failures is a different problem entirely.
The global conversational AI market is on track to exceed $17 billion by 2026, but the vast majority of deployed systems are still reactive question-answering bots dressed up as assistants. True conversational AI assistants ones that maintain session persistence, execute multi-step tasks, and ground responses in live knowledge require deliberate architectural decisions at every layer.
This guide breaks down exactly how a production-grade conversational AI assistant works: the NLU pipeline, memory types, RAG integration, tool orchestration, and the failure modes that kill real deployments.
What Is a Conversational AI Assistant?
A conversational AI assistant is an LLM-powered system designed to engage in multi-turn dialogue, maintain context across exchanges, retrieve relevant knowledge, and take actions on behalf of a user all through natural language.
The key distinction from a simple chatbot lies in three architectural properties: persistent memory, grounded retrieval, and tool access. According to the natural language processing pipeline that underlies these systems, the assistant must handle intent recognition, dialogue state tracking, and response generation as coordinated components not isolated steps.
A chatbot responds. A conversational AI assistant reasons, retrieves, and acts.
How Does a Conversational AI Assistant Actually Work?
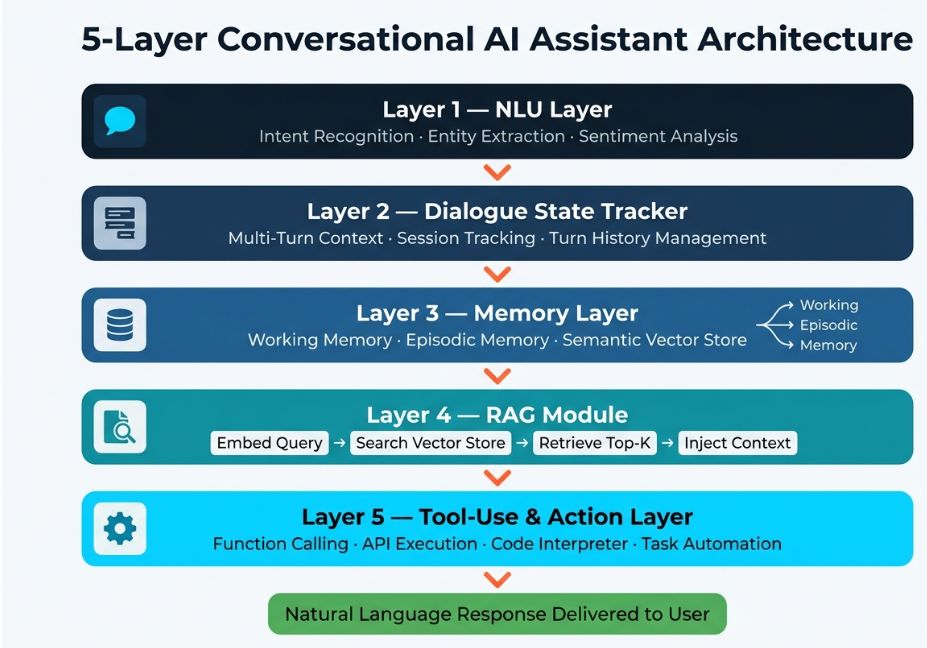
Under the hood, a production-grade assistant is a composition of five interacting layers.
1. Natural Language Understanding (NLU) Layer Incoming user text is parsed for intent, entities, and sentiment. Modern LLM-based assistants handle this implicitly through attention mechanisms rather than explicit intent classifiers, but the function is the same: transform raw input into structured meaning.
2. Dialogue State Tracker The system tracks what has been said, what the user wants, and where in a multi-turn conversation the session currently sits. This is where most naive implementations break they forget state between turns or lose context beyond a few exchanges.
3. Memory Layer This is the most architecturally critical component. Memory in a conversational AI assistant operates across three tiers:
- Working memory: The active context window what the model is reasoning about right now.
- Episodic memory: Summaries or compressed records of past sessions, retrieved on demand.
- Semantic memory: Long-term user facts and preferences, stored in a vector database and retrieved via embedding similarity.
4. Retrieval-Augmented Generation (RAG) Module Instead of relying solely on parametric knowledge baked into model weights, a RAG-enabled assistant queries a vector store at inference time. This grounds responses in current, domain-specific information and significantly reduces hallucination rates.
5. Tool-Use / Action Layer Function calling (via OpenAI Function Calling or LangChain tool agents) allows the assistant to interact with external APIs, databases, calendars, or code interpreters. This is what separates an assistant that answers questions from one that completes tasks.
Architect’s Note: The transition from a chatbot to a true conversational AI assistant happens when all five layers are connected. Remove persistent memory and you have a stateless Q&A bot. Remove RAG and hallucination rates spike on domain-specific queries. Remove tool access and the assistant can advise but never act.

Memory Architecture: The Make-or-Break Layer
The single most common failure pattern in conversational AI deployments is inadequate memory design. Most LLMs are fundamentally stateless each API call has no knowledge of what came before unless that history is explicitly passed in the prompt. Context windows help, but they are bounded and expensive to fill entirely.
The conversational memory patterns in LangChain offer a useful taxonomy that most production teams converge on:
- ConversationBufferMemory: Stores raw message history. Simple, but context windows fill fast in long sessions.
- ConversationSummaryMemory: Uses a secondary LLM call to compress history into a running summary, trading recall precision for token efficiency.
- Vector store-backed memory: Encodes past exchanges as embeddings and retrieves semantically relevant history on each turn the most scalable approach for long-running assistants.
For cross-session persistence where an assistant must remember a user across days or weeks Mem0’s production memory benchmarks (Chhikara et al., 2026) showed that a hybrid graph-and-vector memory architecture significantly outperforms pure buffer approaches on multi-hop and temporal queries, with up to 29.6-point accuracy gains on time-sensitive recall tasks.
python
# LangChain: ConversationSummaryMemory with OpenAI
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryMemory
llm = ChatOpenAI(model="gpt-4o", temperature=0.3)
memory = ConversationSummaryMemory(
llm=llm,
return_messages=True)
assistant = ConversationChain(
llm=llm,
memory=memory,
verbose=False)
response = assistant.predict(
input="I need to analyze our Q2 churn rate and compare it to Q1.")
print(response)Technical Disclaimer: Code examples use LangChain v0.2 and LangGraph v0.2 as of mid-2026. Always check the official LangChain documentation for the latest API surface before deploying.
RAG Integration: Grounding Your Assistant in Real Knowledge
A conversational AI assistant without retrieval grounding is a hallucination machine. Retrieval-Augmented Generation (RAG) solves this by coupling the LLM’s generative capability with a real-time query against a vector store containing your domain documents.
The RAG loop inside a conversational assistant works as follows:
- The user’s query (and relevant conversation history) is embedded into a vector representation.
- Nearest-neighbor search retrieves the top-k relevant document chunks from the vector store.
- Retrieved context is injected into the LLM’s prompt as grounding material.
- The LLM generates a response bounded by the retrieved facts rather than parametric memory alone.
LlamaIndex’s agentic framework makes this composable developers can attach RAG pipelines directly to agent tool calls, so the assistant only triggers retrieval when the query actually requires external knowledge. This hybrid approach (retrieval-on-demand rather than retrieval-always) reduces latency and avoids polluting the context window with irrelevant chunks.
Did You Know? A 2026 Zendesk production analysis reported a double-digit drop in wrong answers when LLM responses were grounded in retrieved documentation vs. purely parametric generation a consistent finding across enterprise deployments.
RAG vs. Full-Context Comparison
| Approach | Latency | Accuracy on Domain Queries | Token Cost | Hallucination Risk |
|---|---|---|---|---|
| Parametric only (no RAG) | Low | Poor on niche topics | Low | High |
| Full-context stuffing | High | Good | Very High | Medium |
| RAG (top-k retrieval) | Medium | Strong | Medium | Low |
| Agentic RAG (on-demand) | Medium | Strongest | Medium | Lowest |
Conversational AI Assistant Use Cases 5 Real-World Deployments
1. Enterprise Knowledge Assistant Internal teams query a vector-indexed knowledge base of policies, SOPs, and product docs. The assistant retrieves relevant chunks, maintains dialogue context across follow-up questions, and cites its sources. Reduces time-to-answer by orders of magnitude vs. wiki search.
2. Customer Support Agent The assistant handles Tier-1 queries autonomously using RAG over help center content, escalates to humans when confidence is low, and maintains conversation history so users don’t repeat themselves. Intercom’s Fin built on this architecture was shipped in eight weeks on top of scraped help center content.
3. Developer Copilot Using OpenAI Function Calling or LangGraph tool nodes, the assistant queries GitHub issues, reads pull request diffs, runs code via a code interpreter tool, and summarizes findings in natural language all within a single conversational loop.
4. Healthcare Information Assistant A RAG-grounded assistant indexed over clinical guidelines answers patient intake questions, flags out-of-scope medical advice, and routes complex queries to human practitioners maintaining HIPAA-compliant session logs.
5. Personal Productivity Assistant Tools like Saner.AI demonstrate how a conversational AI assistant with cross-session episodic memory can plan the user’s day, surface relevant past notes, and generate action plans without the user restating context on every session.
Common Mistakes and How to Avoid Them
Mistake 1: No context window management strategy Naively stuffing all conversation history into every prompt works in demos and breaks in production at turn 20. Use summary memory or vector-backed retrieval to compress history intelligently.
Mistake 2: RAG without reranking Top-k vector search retrieves semantically similar chunks not necessarily the most relevant ones. Add a cross-encoder reranker (e.g., Cohere Rerank or BGE-Reranker) after initial retrieval to improve chunk selection.
Mistake 3: No hallucination guardrails LLMs will generate confident-sounding but incorrect responses when retrieved context is ambiguous. Implement a grounding check: if retrieved chunks do not contain sufficient evidence for a claim, the assistant should say so rather than fabricate.
Mistake 4: Single-turn tool calls Many implementations fire one tool call and return. Production assistants need a ReAct-style loop (Reason + Act, Yao et al., 2023) the model reasons about the tool output, decides whether the result is sufficient, and calls additional tools if needed before returning a final answer.
Mistake 5: Missing fallback and escalation logic An assistant with no escalation path will attempt to answer every query, compounding errors. Build explicit confidence thresholds: when retrieval score is below a threshold or the query is out of domain, hand off to a human or respond with appropriate uncertainty.
Pro Tip: Track your assistant’s tool call failure rate and empty-retrieval rate in production. These two metrics more than BLEU or ROUGE scores will tell you whether your architecture is actually working.
What Developers Are Saying
Discussion threads on r/LocalLLaMA and GitHub Discussions around LangGraph and Mem0 consistently surface the same theme: the hardest part of building a production conversational AI assistant is not the LLM itself it is state management, memory persistence, and graceful degradation when retrieval fails.
A common pattern reported by practitioners: assistants that perform excellently in 5-turn evaluations collapse in 25-turn production conversations because no one designed the memory compression strategy for long sessions.
FAQ People Also Ask
What is the difference between a conversational AI assistant and a chatbot?
A chatbot follows pre-defined rules or scripted decision trees and responds to one query at a time. A conversational AI assistant uses a large language model with persistent memory, multi-turn dialogue tracking, and tool access to reason across exchanges and complete tasks not just answer questions. A chatbot becomes an assistant when you add tools, planning, and cross-session memory.
How does a conversational AI assistant remember context?
Context is maintained through a combination of in-window message history, summarization memory (compressing older turns into summaries), and vector-backed episodic retrieval (encoding past conversations as embeddings and fetching relevant ones on demand). Production systems use all three tiers, balancing token cost against recall fidelity.
What is RAG and why does it matter for conversational AI?
Retrieval-Augmented Generation grounds the LLM’s responses in documents retrieved from a vector store at inference time, rather than relying solely on knowledge baked into model weights. For conversational AI assistants, RAG dramatically reduces hallucination on domain-specific queries by giving the model verified, up-to-date source material to reason over.
How do I build a conversational AI assistant with memory?
The fastest production path in 2026 is LangGraph or LlamaIndex with a summary memory layer for in-session context and Mem0 or Zep for cross-session persistence. Index your domain documents into a vector store (Pinecone, Qdrant, or Chroma), attach RAG as a tool call, and implement a ReAct loop for multi-step reasoning. See the code example in the Memory Architecture section above.
What are the most common failure modes in conversational AI?
The five most common failure modes are: context window overflow in long sessions, hallucination from insufficient RAG grounding, tool-call loops that don’t terminate, missing escalation logic for out-of-scope queries, and session state loss between deployments due to no persistent memory backend.
Conclusion
Building a production-grade conversational AI assistant comes down to three architectural decisions: how you manage memory across turns and sessions, how you ground responses in retrieved knowledge to reduce hallucination, and how you design the tool-use loop to handle multi-step tasks without getting stuck. The LLM is the easy part it is the orchestration layer that separates demos from deployments.
Framework choices matter, but the patterns matter more. Whether you are using LangGraph, LlamaIndex, or a custom stack, the conversational AI assistant that performs in production is the one where the memory, RAG, and ReAct loop are designed deliberately not bolted on as an afterthought.
Explore more hands-on AI agent tutorials and agentic workflow breakdowns at agentiveaiagents.com.





10 Comments